System Demonstration Videos
Overview Video
Comprehensive overview of the MISAR system demonstrating multimodal AR instructional capabilities.
System Screen Recording
Screen recording demonstration showcasing the MISAR system interface and real-time processing capabilities during task execution.
Live Scene Description Recording
Live demonstration of streaming scene description with Jing showcasing real-time multimodal understanding and response generation.
Hand Tracking System Showcase
Multimodal Integration
Seamless integration of visual, auditory, and linguistic channels for optimized human-computer interaction in AR environments. Our system leverages GPT-3.5-Turbo as the central reasoning component for contextual understanding.
LLM-Enhanced AR
Novel application of Large Language Models in augmented reality for task performance quantification through egocentric video analysis, speech processing, and contextual modeling for intelligent user assistance.
System Architecture
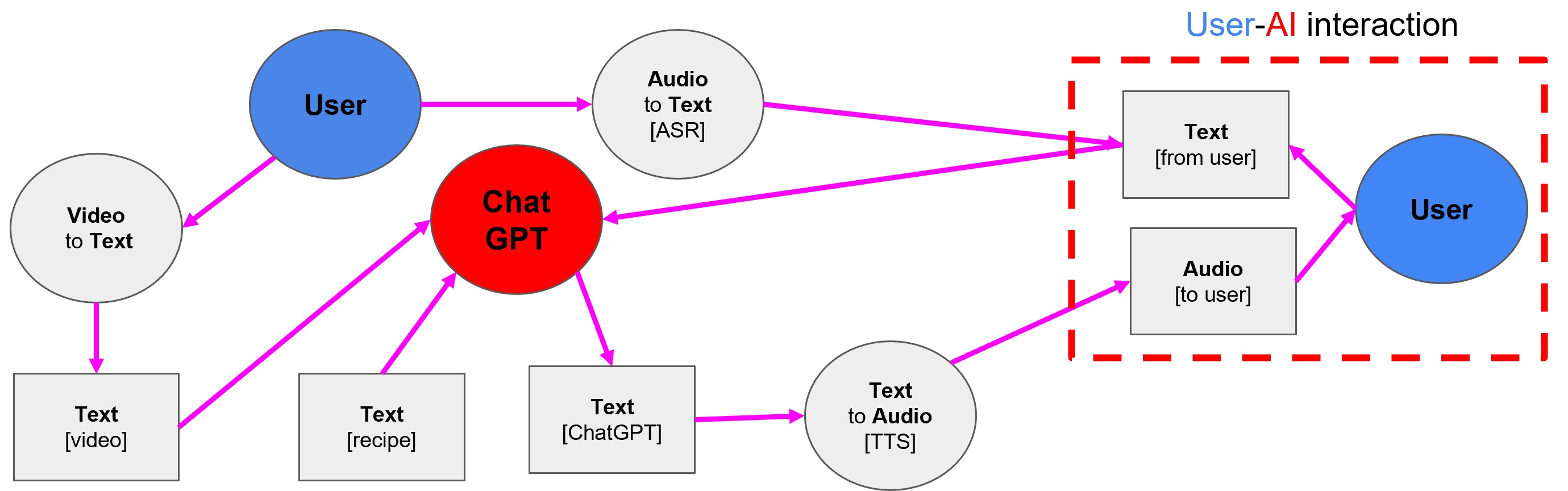
Architecture of the proposed multimodal integration model, highlighting GPT-3.5-Turbo as a central component. The model seamlessly integrates video-to-text, text-to-speech, audio-speech recognition, and GPT-3.5-Turbo for comprehensive AR assistance.
Our system integrates ASR technology to transcribe verbal inputs into textual format, which is synergistically coupled with audiovisual data streams captured by the HoloLens2 camera.
This enables comprehensive perspective acquisition of the user's visual field. The video footage is processed to generate summarizations and textual descriptions,
while LLMs serve as the computational epicenter, fulfilling dual roles: answering user questions and augmenting the fidelity of video description captioning.
Key Components
The MISAR system consists of several integrated components:
• Video-to-Text Conversion: Using LaViLa model pre-trained on Ego4D dataset for accurate video understanding and description generation
• Speech Processing: Google ASR and TTS APIs for seamless speech-to-text and text-to-speech conversion
• Recipe-based Dialog: Contextual conversation system for step-by-step guidance and error correction
• Enhanced Captioning: GPT-3.5-Turbo integration for improving video caption quality and contextual relevance
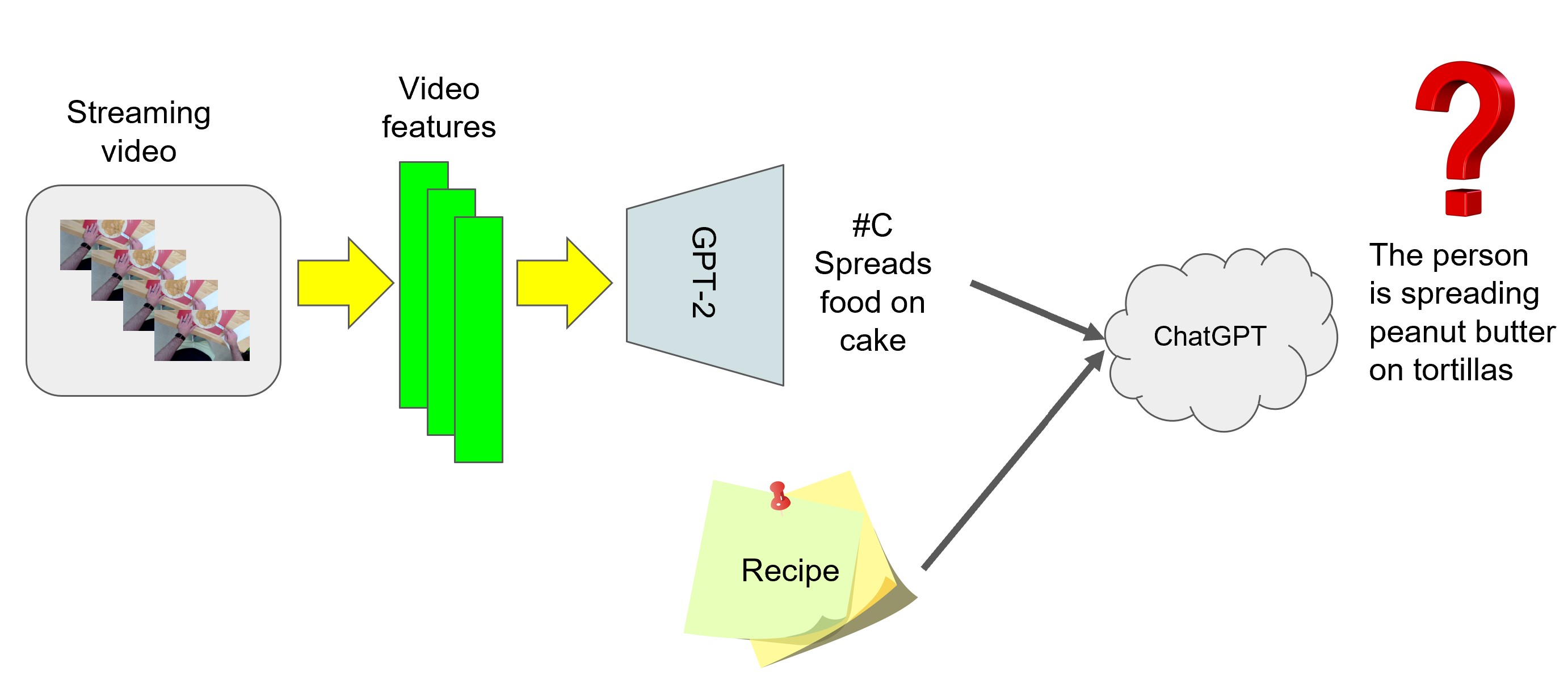
Architecture showcasing the integration of GPT-3.5-Turbo into the workflow. By incorporating GPT-3.5-Turbo, we enhance the quality of generated text descriptions and establish a seamless means of communication between instructional input, users, and video content. The system enables dynamic interaction where users can provide instructions or ask questions related to specific video segments, leading to improved accuracy and richness of textual labels.
Recipe-based Instructional Dialog
Our system features an advanced conversation capability focused on the most frequently asked questions in support systems:
• Asking for Step Instructions: Questions about next/previous steps and detailed step descriptions. These require understanding conversation context, recipe knowledge, and current user state.
• Asking for Error Correction: The system provides solutions to rectify mistakes by combining generalized domain knowledge with contextual understanding of the user's current situation.
Enhanced Video Captioning with LLMs
By integrating GPT-3.5-Turbo into the workflow, we enhance generated text descriptions and establish effective communication between instructional input, users, and video content.
The integration allows for seamless interaction where users can provide instructions or ask questions related to specific video segments, with GPT-3.5-Turbo responding with informative and contextually relevant explanations.
This dynamic interaction improves the accuracy and richness of generated video-to-text labels while empowering users to actively engage with content.
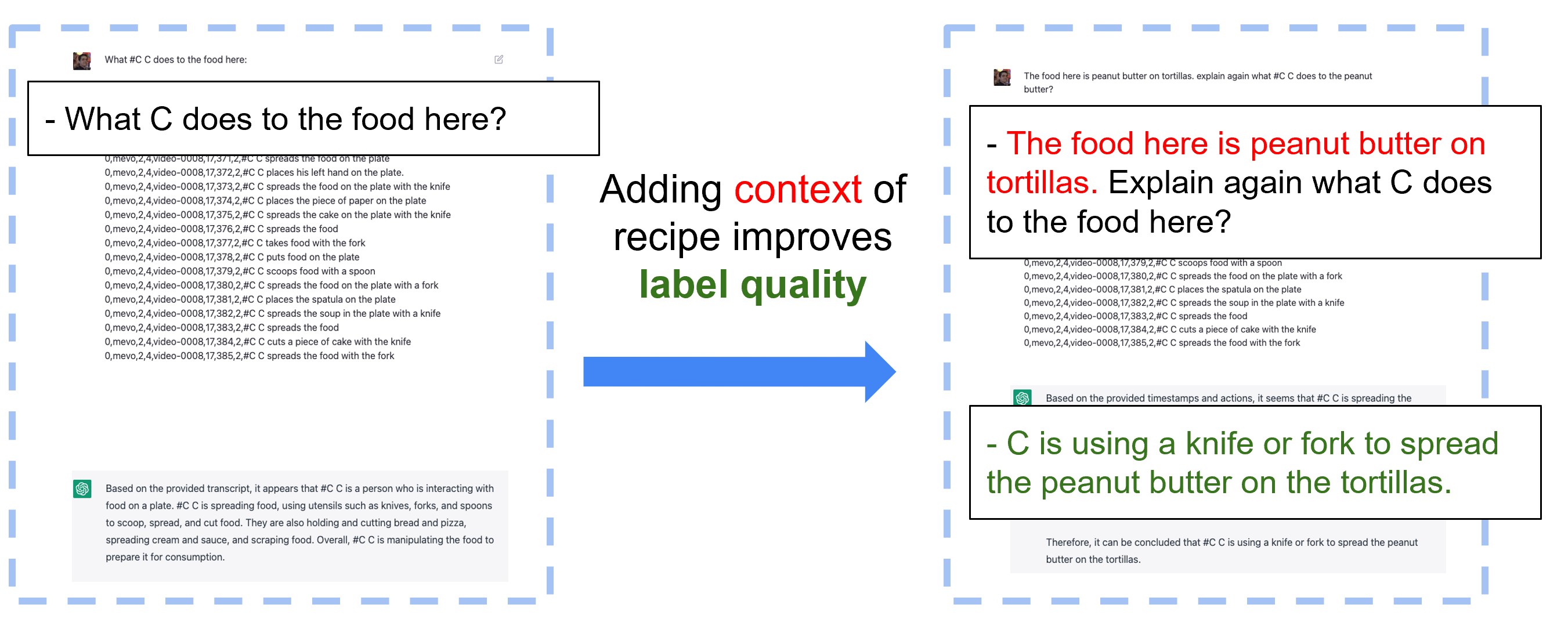
The impact of leveraging larger models such as GPT-3.5-Turbo on enhancing the quality of textual labels within the given context. Leveraging larger LLMs and inclusion of contextual information such as recipes or instructions significantly improve the accuracy and richness of generated textual labels, leading to better understanding and interpretation of the content.
Video-to-Text Scaling with LLMs
Based on our observations, we propose an enhanced metric to more effectively capture attention head behavior
across different datasets. Specifically, we recommend not only using attention weights but also
incorporating a concentration score as a complementary dimension. This concentration score quantifies how
narrowly or broadly a model head focuses on particular regions within an image as it processes each layer.
Together, these metrics form a two-dimensional representation that offers a more comprehensive view of the
model’s attention patterns.
Results and Discussion
The results show that text polished with LLMs was significantly more relevant to the context under consideration. From the trained video-to-text model with general data, we made the generated text more contextual, opening potential for reducing the domain gap between pretrained models and domain-specific data without requiring fine-tuning.
Demo and System Validation
We demonstrate the efficacy of our dialog system through a live demo. The system is user-friendly and capable of providing immediate responses to user inquiries. During evaluation, the system was subjected to various question types, including task completion descriptions and troubleshooting procedures for errors.
Key Findings
Our experiments demonstrate several important findings:
- Multimodal Integration: Seamless combination of visual, auditory, and linguistic channels enhances AR user experience significantly
- LLM Enhancement: GPT-3.5-Turbo integration substantially improves video caption quality and contextual relevance
- Recipe Context Impact: Medium-length recipe descriptions yield captions most closely aligned with intended context
- Real-time Performance: System achieves real-time caption generation suitable for AR applications
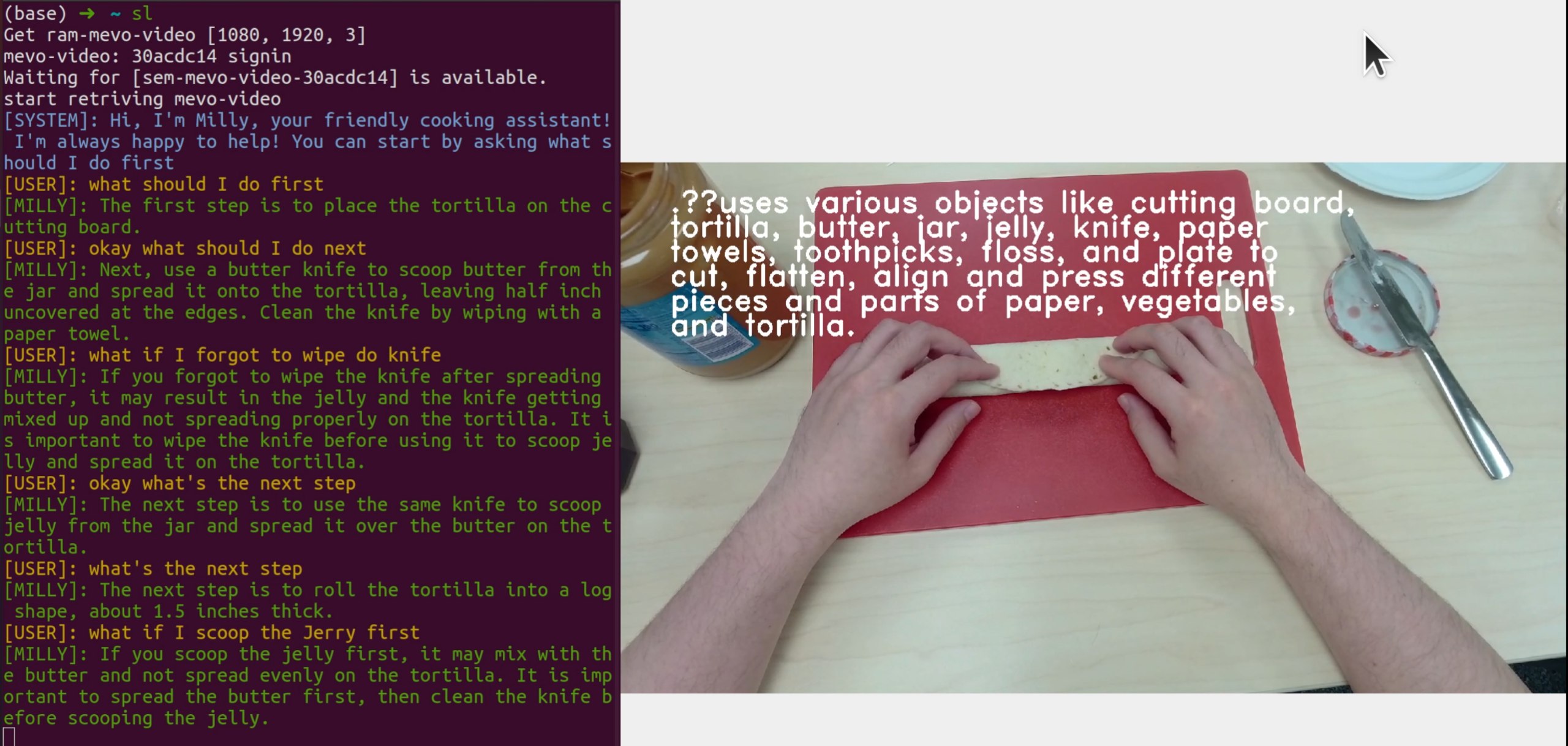
Screenshot of the demo showcasing the dialog system. The system demonstrates user-friendly interaction capabilities with immediate responses to user inquiries, including task completion guidance and error troubleshooting. Full video demonstration available in the GitHub repository.
System Features
User-AI Interaction
Conversational interface through AR glasses enabling streamlined human-computer interaction predominantly through speech. The experience emulates collaboration with a seasoned expert, elevating overall task performance.
Scalable Solution
Cost-effective alternative to traditional training methods eliminating the need for specialized instructors. Provides scalable solution for enhancing human performance while reducing associated training costs.
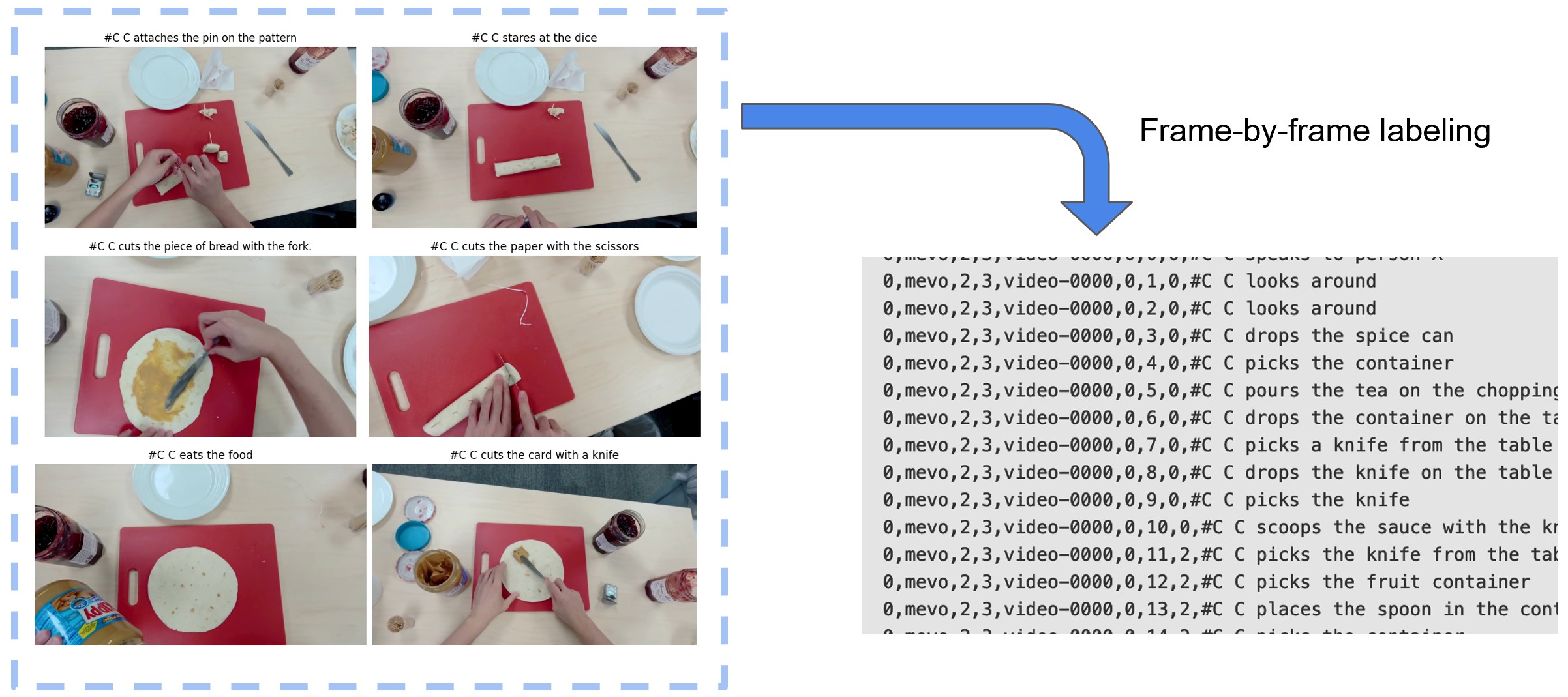
Automating frame-by-frame labeling and annotation of video files through video-to-text conversion models.
This scalable approach enables efficient natural language labeling across diverse domains, though generated text may sometimes contain noise or lack environmental dynamics.
Citation
If you found this work useful in your own research, please consider citing the following.
@article{bi2023misar,
title={MISAR: A Multimodal Instructional System with Augmented Reality},
author={Bi, Jing and Nguyen, Nguyen and Vosoughi, Ali and Xu, Chenliang},
journal={Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshop on AV4D: Visual Learning of Sounds in Spaces},
year={2023}
}



